서버 / IT [강좌]이중화기술 - 가용성과 경제성
2011.01.06 09:32
오래전에 후배들을 위해 만든 문서인데... 복사해 붙이다보니 개요 맞추기가...
==============================================================
이중화 기술
- 최소 비용으로 가용성을 키워라
1. 개요
이중화 기술이란 복수의 노드(System) 또는 장치(Device)를 이용해 서비스를 구성하여, 장애 발생 시에도 가용성(Abailability)을 극대화시키는 것으로, 작게는 CPU나 NIC(랜카드)와 같은 부품 이중화에서부터 크게는 원격지 백업 서비스까지 포함하는 모든 가용성 기술을 통칭한다.
2. 이중화 기술의 종류
2.1 듀얼 Device
가. CPU와 메모리의 이중화
현존하는 거의 대부분의 컴퓨터 시스템은 CPU나 메모리에 물리적 장애가 발생하였을 경우 시스템 패닉(Panic)이 일어나며 그 순간까지의 작업 내용을 디스크에 내려 저장하면서 재부팅되거나 시스템이 다운된다. 단일 CPU나 단일 메모리 모듈이 아닐 경우 재부팅하면서 문제의 장애 파트를 버리고 나머지 자원만으로 시스템을 운영한다(재부팅이나 장애처리 동안 서비스 중단).
메인프레임과 같은 대형 시스템은 이와 같은 상황에 대비하기 위하여 칩킬(Chip Kill)이라는 기술을 사용한다. CPU에서는 여러 개의 CPU를 몇 개의 모듈(MCM, Multi Chip Module)로 구성하여 고장난 CPU가 포함된 CPU모듈을 온라인 중에 연산에서 제거하면서 서비스를 유지하고, 메모리에서는 에러 보정 기능이 있는 ECC메모리를 사용하여 복수의 메모리칩에 데이터와 패리티를 분산 기록하고 고장난 메모리칩을 온라인중에 제거하면서 패리티를 이용해 연산을 복구하며 서비스를 지속한다.
시스템의 뼈대를 구성하는 메인 플래너에는 여러 가지 칩셋이 포함되어 있는데, 대표적인 것인 BIOS 칩셋, CPU와 메모리 간의 통신을 관장하는 칩셋, 그리고 PCI 버스를 관장하는 칩셋 등이다. 최근에는 안정적인 시스템을 구성하기 위하여 이러한 칩셋들도 이중으로 장착하는 경우가 늘고 있다.
나. 디스크 이중화와 레이드(RAID) 기술
디스크 Fault는 그 자체로 서비스 장애는 물론이고, 데이터 손실과 시스템을 부팅 불능 상태로까지 몰고가는 치명적 장애 중의 하나이다. 디스크 장애에 대비하는 기술은 오래 전부터 지속적으로 진보하고 있는데 대표적인 것이 RAID(Redundant Array of Independent Disks) 기술이다.
1) RAID의 정의
기본적인 개념은 경제적 가치가 없어진 소용량 디스크들을 논리적으로 연결하여 크고 비싼 디스크 하나로 대체하는 것이다. 즉, 여러 개의 디스크에 데이터와 패리티 정보를 배치하여 속도와 안전성, 고용량을 구현할 수 있게 된다.
- 장애 발생요인을 최대로 제거한 고성능의 무정지 대용량 저장장치 구현 가능
- 여러 개의 HDD를 하나의 Virtual Disk로 구성하므로 대용량 저장 창치 구축가능
- 다수의 HDD에 Data를 분할하여 병렬 전송함으로써 전송 속도 향상
- 시스템 가동 중 Disk Module 고장 시에도 시스템 정지 없이 새 Disk로 교체하면서 원래의 데이터를 자동복구
2) RAID의 장점
퍼포먼스, 안정성, 용량과 경제성 등을 서비스나 시스템의 목적에 따라 효과적이고 경제적으로 구성할 수 있다는 게 RAID 기술의 가장 큰 장점이다. 예를 들면 미러링 기법은 구성이 간결하고 안정적이지만 투입된 디스크의 절반만을 사용 공간으로 제공하므로 경제성이 낮아진다.
3) RAID Level
각 RAID 레벨은 비용과 속도에 대한 상반되는 요구를 절충하여 각기 다른 방법으로 여러 드라이브 사이에 데이터를 분산시킨다. 즉 RAID의 각 레벨은 서로 다른 용도를 위해 최적화된 디스크 저장 시스템이다.
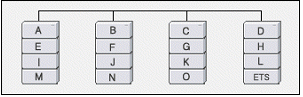
가) Raid 0 (Striping)
RAID level 0는 데이터를 각 디스크에 병렬로 분산 저장(striping)하므로 속도가 매우 빠르고 경제적이다. 다만, 하나의 디스크에 장애가 발생하면 RAID 구성 자체가 파괴되므로 모든 데이터를 잃게 된다.
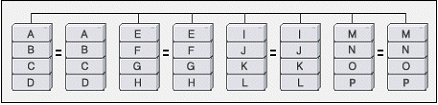
나) Raid 1 (Mirroring)
RAID level 1은 한 드라이브에 기록되는 모든 데이터를 다른 드라이브에 복사(mirroring)해 놓는 방법으로 복구능력을 제공한다. Level 1 array는 하나의 드라이브를 사용하는 것에 비해 약간 나은 정도의 성능을 제공한다(읽을때 더 빠르며, 쓸때는 약간 느리다. 하지만 패리티를 계산하지 않기 때문에 RAID4나 5보다는 빠르다). 이 경우 어느 디스크 드라이브가 고장나더라도 데이터의 손상은 일어나지 않는다. 하지만 전체 용량의 절반이 여분의 데이터를 기록하기 위해 사용되기 때문에 저장 용량당 단가가 비싸다.
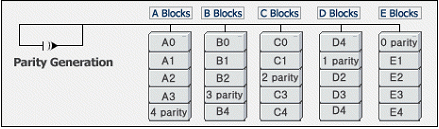
다) Raid 5
RAID level 5는 패리티 정보를 모든 드라이브에 나누어 기록한다. 패리티 정보는 어느 한 드라이브에 장애가 발생했을 때 데이터를 복구할 수 있게 해 준다. 패리티를 담당하는 디스크가 병목현상을 일으키지 않기 때문에, level 5는 멀티프로세스 시스템에서와 같이 작고 잦은 데이터 기록이 있을 경우 더 빠르다. 하지만 읽어들이기만 할 경우 각 드라이브에서 패리티 정보를 건너뛰어야 하기 때문에 상당히 느리다. 용량당 비용은 디스크 한 개의 비용만큼만 더 들어가므로 꽤 경제적인 셈이다.
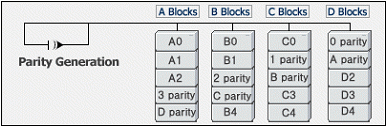
라) Raid 6
패리티 정보를 이중으로 기록하므로 RAID 5보다 안정성이 높아지지만 입출력이 잦을 때 패리티 정보 갱신을 위한 병목이 발생하여 속도가 현저하게 느려진다. 비용은 비싼 편이 아니지만 퍼포먼스 때문에 잘 사용하지 않는다. 다만 초고용량 볼륨을 위해서 디스크를 10개 이상 사용할 경우 디스크 장애 확률이 높아지기 때문에 고려할만 하다.
마) Raid 10과 0+1
RAID10과 0+1은 비슷하면서도 다르다. 비슷한 면으로는 용량과 퍼포먼스가 같다는 정도고, 다른 면으로는 기술적으로 RAID10이 복잡하고 안정적인 반면 RAID0+1은 단순하지만 안정성이 떨어진다는 정도이다.
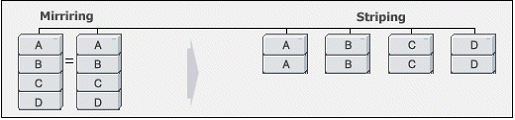
① RAID 10의 구성
RAID1로 구성한것을 RAID0로 묶는 구조로, RAID10으로 8개의 HDD를 묶는다고 하면,
- RAID1으로 2개씩 묶어서 4개의 RAID1 볼륨을 만든다. RAID1[1,2], RAID1[3,4], RAID1[5,6], RAID1[7,8] 이렇게 4개가 나오는데, 각각 R0, R1, R2, R3라고 이름 짓는다.
- RAID0로 4개를 묶는다. RAID0[R0,R1,R2,R3]이 되는데, 이것을 풀어서 보면 RAID0[RAID1[1,2],RAID1[3,4],RAID1[5,6],RAID1[7,8]] 이렇게 된다.
② RAID 0+1의 구성
RAID0으로 구성한 다음 RAID1으로 미러링을 하는 구조로, 예를 들어 RAID0+1로 8개의 HDD를 묶는다고 하면,
- RAID0으로 4개씩 묶는다. RAID0[1,2,3,4], RAID0[5,6,7,8] 이렇게 2개의 묶음을 R0, R1이라고 이름 짓는다.
- RAID1으로 2개를 묶는다. RAID1[R0,R1]이 되는데, 이것을 풀어서 보면 RAID1[RAID0[1,2,3,4],RAID0[5,6,7,8]] 이렇게 들어가는 것을 알 수 있다.

③ Raid 10과 0+1의 안정성 차이
RAID0+1에서 RAID1[RAID0[1,2,3,4],RAID0[5,6,7,8]]가 있는데, 1번 하드에 장애가 발생하였을 경우, RAID0[1,2,3,4]는 통째로 RAID 구성이 깨진다. RAID 0는 하나라도 문제가 생기면 볼륨 전체가 중지되어 버린다. 반면에 RAID10은 RAID0[RAID1[1,2], RAID1[3,4],RAID1[5,6],RAID1[7,8]]에서 1번하드가 고장나면, RAID1[1,2]가 Mirroring이기 때문에 1,2가 동시에 문제가 생기지 않는 한은 RAID1은 중지되지 않는다. 이를 확장해서 보면 RAID 0+1의 경우는 R0에서 하나, 그리고 R1에서 하나만 문제가 생기면 전체 RAID 시스템의 구성이 완전히 파괴된다. 그러나 RAID10의 경우는 1,3,5,7 4개의 하드가 동시에 깨져도 문제없이 동작한다. 확률적으로 RAID 10이 훨씬 나은 안정성을 제공하게 된다.
④ Raid 10과 0+1의 디스크 복구 차이
RAID0+1의 경우 1번 하드가 깨진 경우, 1번 하드를 교체한 후에 Rebuild를 하게 되면 R1에서 R0을 통채로 복사하게 된다. 반면 RAID10의 경우 1번 하드가 깨진 경우, 1번 하드를 교체후 Rebuild를 하면 2번 하드에서 1번 하드로 복사를 하게 됩니다. RAID10의 경우 시간이 엄청나게 단축되는 이점이 있다.
다. PSU 및 Device Adapter의 이중화
- 최근에 PSU(전원공급장치, Power Supply Unit)를 이중화 하는 것은 모든 전산 시스템에서 Default 사양이다. 이에 더하여 Rack의 PDU(전원배분장치, Power Distribution Unit)로 인입되는 전원 자체를 이중화하는 것은 물론이고 분전반이나 건물로 인입되는 전력원을 서로 다른 발전소에 연결되도록 전술적으로 구성하는 것도 보편화 되어 있다.
- NIC(랜카드, Network Interface Card)나 FC(Fibre Channel) 어댑터 등과 같은 외부 연결 장치들도 최근에는 반드시 이중화하는 게 추세이고, 더하여 멀티 어댑터에 멀티 포트로 구성하여 장애발생 시에도 실시간으로 절체(take over, fail over)함으로써 서비스 가용성을 극대화 한다. 기술적인 배경은 복수의 Device에 하나의 논리적 접속점(ex. ip address)을 부여하여 가용한 Device로 항상 연결되게 하는 것이다.
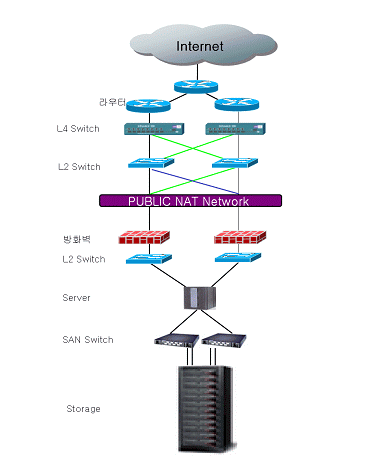
라. 스토리지, 스위치의 이중화
- 스토리지서버(디스크 어레이 장치에 운용 시스템이 결합되어 있는 저장 시스템)에는 다양한 이중화 기술이 집약되어 있다. 그만큼 에러 포인트가 많다는 뜻이기도 한데, 우선 디스크 어레이 자신이 RAID 기술로 구성되어 있고, 전원공급장치 역시 이중화되어 있으며, RAID를 구성하는 컨트롤러 역시 듀얼로 구성되어 있고, 호스트나 스위치와 연결되는 포트 역시 복수로 구성된다. 이러한 여러 개의 안전장치들을 구비한 스토리지서버는 서비스 미션에 따라, 무중단 서비스를 위한 고가의 장비에서부터 소용량 고성능 장비, 대용량 저가 장비 등 다양하게 구성된다. 미션 크리티컬 서비스의 경우 스토리지서버 자체를 두 대로 운용하는 스토리지 이중화 기법을 사용하기도 한다.
- SAN이나 네트워크 스위칭 장비를 이중화하여 사용하고자 할 때에는 이에 접속하고자 하는 노드 자신의 어댑터(NIC, FC카드)가 먼저 이중화되어야 한다. 이 방법은 어댑터나 링크, 스위치 등 어느 곳에서 장애가 발생하더라도 서비스 가용성을 확보할 수 있고, 동시에 Active-Active 방식으로 운용될 경우 부하분산(Load Balancing)의 효과도 기대할 수 있다.
마. 서비스 프로세스의 이중화
서비스 프로세스를 여러 개 띄우는 것도 값싸고 효과적인 이중화 기술 중의 하나이다. 예를 들어 하나의 시스템에 똑같은 웹서버(httpsd)의 config 파일(httpsd.conf)를 여러 개 만들어 띄운다면 웹서버 한두 개가 죽어도 서비스를 유지할 수 있을 것이다. 이 방법을 수행하기 위해서는 몇 가지 전제 조건이 필요하다. 공유할 수 있는 자원(ex. Document Root)은 공유하되 그렇지 못한 자원(ex. Service Port)은 구분해 주어야 하고, 서버의 상황을 지속적으로 감시하여 정확하게 매핑시켜 줄 스위칭장비(L4스위치)가 있어야 한다. 서버의 자원에 여유가 있다면 L4스위치는 여러 개의 웹서버로 부하를 분산시켜 서비스 성능을 증가시킬 수 있고, 각각의 웹서버 포트를 감시하여 Down된 포트가 감지되면 사용자의 요청(Request)을 다른 활성포트의 웹서버로 돌려주면 된다.
2.2 SLB(Server Load Balancing)
사용자가 많지 않을 경우에는 단지 1~2대의 서버를 두고 캐싱 기술을 사용하여 어느 정도 원활한 서비스를 제공할 수 있으나, 사용자의 수가 늘어감에 따라 동시 접속 사용자 수도 늘어나게 되어 정체 현상이 발생하게 될 것이다. 이럴 때는, 여러 대의 서버를 부하분산 스위치에 연결하여 동시 접속 사용자들의 요청(Request)을 여러 대의 서버에 고르게 분산시켜서 원활한 서비스를 제공하는 SLB 기술을 사용하는 것이 효과적이다. 특히 웹 기반의 인트라넷, 쇼핑몰, 검색엔진, 사이버주식 조회/거래, 사이버스쿨 등과 같이 다수의 사용자들이 동일한 내용(Content)에 동시에 액세스하면서도 그들의 서비스 이용이 서버의 데이터를 변화시키지 않는다면(read only operation) 여러 서버에 동일한 데이터를 넣어 두고 부하분산 기술을 사용하는 것이 특히 효과적이다.
▷ SLB의 작동 원리
- Load balancing 시키고자 하는 서버들에 하나의 가상 IP를 부여
- 가상 IP로 서비스를 받는 세션이 시작되면 L4 스위치에서 이를 탐지
- L4 스위치는 Load가 가장 적은 서버로 새로운 세션을 forwarding
- 세션이 끝날 때까지 같은 서버로 해당 세션의 패킷들을 forwarding
- 서버들과 application들은 지속적인 감시를 받음
▷ L4 스위치를 이용한 SLB의 이점
- L4 스위치에서 서버들을 지속적으로 감시함으로써 black hole 현상 방지
- Server들의 performance 변화에 따른 load 분배 가능(가중치 설정)
- Application 서버(HTTP, FTP, DNS, RADIUS 등등)들에 대한 backup server 구성을 용이하게 함 : 백업서버 한 대에 https, ftp, dns 등의 서비스를 올려놓고 메인서비스가 다운될 경우 스위치는 백업서버로 사용자 요청을 forwarding한다.
- ASP(Application Service Provider)들에게 server farm을 통한 대형 사이트를 구축할 수 있는 핵심 기술 제공
2.3 HA Clustering
HA(High Availability)는 고가용성을 의미한다. HA와 클러스터(Cluster)라는 용어는 엄밀히 말하면 다르지만, 고가용성이라는 의미로 혼용해 사용하고 있다. 아마도 몇몇 HA 제품들의 명칭에 클러스터라는 단어가 사용되고 있기 때문일 것이다.
HA는 복수의 시스템 노드를 이용하여 적은 비용으로 높은 가용성(Availability)을 얻는 이중화 기술이며 SLB와 다른 점은 데이터의 신뢰성이 요구되는 서비스 특성상 하나의 resource(공유 디스크 볼륨, 서비스 IP 주소)를 운용해야 한다는 것이다.
HA의 목적은 서비스의 다운타임(99.99%의 가용성을 갖는다 해도 다운타임은 1년에 52분이나 된다)을 최소화함으로써 가용성을 극대화하자는 것이다. 운영 서버에 장애가 발생하더라도, 대기 서버가 즉시 서비스를 대신 처리해 준다면 서비스의 다운타임은 최소화될 수 있다. HA는 관리자가 없을지라도 운영 서버의 장애를 모니터링해 대기 서버가 처리할 수 있도록 함으로써 중단 없이 서비스를 제공하는 역할을 한다.
가. HA 기술의 원리
1) 노드 간 감시
HA 클러스터로 구성된 두 대 이상의 시스템(각각을 node라 부름)은 노드 간에 상대 시스템의 상태를 체크한다. 대개 노드 간에는 HeartBeat을 체크할 수 있는 Direct링크를 구성하여 운영하며, 하드웨어 장애(전원, CPU, 메모리, 디스크)와 네트워크 장애(랜카드, 케이블), 그리고 프로세스 장애(DB 및 각종 애플리케이션)를 감지하여 사전에 정의된 에러에 해당되면 장애노드의 모든 서비스를 내리고 대기 중인 노드에서 그 서비스를 수행한다.
2) Resource의 공유와 절체
HA 클러스터에 소속되어 대기 중인 노드는 현재 서비스를 수행하고 있는 노드의 모든 애플리케이션을 기동할 수 있어야 하므로, 서비스 디스크 볼륨(외부 저장장치)에 접근할 수 있어야 하고 서비스 ip 주소를 부여할 여분의 랜카드를 확보하고 있어야 한다. 또한 서비스를 기동할 때 필요한 프로그램과 Configuration이 완비되어 있어야 한다.
장애가 확인되면 대기중인 노드는 공유볼륨 접근을 확인하고 여분의 랜카드에 ip 주소를 할당한 후 애플리케이션을 로딩(웹서버를 띄우거나 DB를 기동하고 Listener를 여는 것 등)한다.
나. HA 클러스터링의 종류
1) Hot Standby(Active-Standby)
- 순전히 대기만을 위한 시스템 노드가 준비되어야 한다. 대기 노드는 공유 볼륨에 접근이 가능한 상태에서 필요한 경우 애플리케이션을 미리 로드해 놓을 수 있지만 서비스를 위한 접속점(ip address, listener)은 활성화되지 않아야 한다.
- 서비스 노드에서 장애가 감지되고, 그것이 사전에 정의된 절체 사유에 해당되면 대기 노드는 절체(Takeover) Procedure를 발행하면서 접속점을 열어 서비스를 시작한다.
- Hot Standby 방식에서 장애 노드의 문제가 모두 해소되었을 경우 원래 노드로 다시 서비스를 자동 절체하는 Auto Failback(또는 Failover) 기능은 서비스 특성에 따라 활성화 또는 비활성화시킬 수 있다.
- 장애 포인트가 적기 때문에 절체 성공률이 높고 절체 후 부하 처리에서 장점이 있는 반면 대기 노드의 자원(Resource)을 서비스에 활용하지 못하기 때문에 비경제적이라는 단점도 있다.
2) Mutual Standby(Active-Active)
- 복수의 노드에서 각 노드는 모두 서비스를 제공하다가 장애 노드가 발생하면 그 서비스를 다른 노드에서 병행 처리해 주는, 독립서비스 & 상호대기 방식이다. 예를 들면 node1은 웹서버로, node2는 메일서버로 사용하다가 node1에 장애가 발생하면 node2는 웹서버와 메일서버를 함께 수행하다가 node1의 장애가 해소되면 서비스를 다시 하나씩 나누어 수행한다.
- 모든 노드는 서비스 노드이면서 동시에 대기 노드 역할을 겸한다.
- 모든 노드는 대기 서비스를 실제로 서비스할 경우에 장애 노드가 복구될 때까지 부하를 감당할 수 있는 최소한의 Resource를 확보하여야 한다.
- 통상 이 방식에서 Auto Failback 기능은 사용하지 않는다.
- 모든 노드에서 서비스가 진행되기 때문에 장애 포인트가 많고 절체 후에도 부하를 감당하지 못해 다운될 수 있는 단점이 있지만 모든 시스템을 서비스에 활용할 수 있다는 경제적 장점도 있다. 무거운 서비스(DB)와 가벼운 서비스(웹, DNS)를 묶어서 구성하면 특히 효과적이다.
3) 다(多)노드 클러스터링
가) 전용대기 방식(Rotating Standby)
세 대 이상의 여러 노드에서 각 노드는 각자의 서비스를 수행하고 하나의 전용 대기 노드를 준비하는 구성으로 하나의 대기 노드는 모든 서비스를 수행할 준비가 되어 있어야 한다.
나) 상호대기 방식
세 노드 이상에서 각기 다른 서비스를 수행하다가 장애 노드가 발생하면 사전에 정의해 둔 우선순위에 의해 다른 서비스를 수행 중인 한 노드로 절체가 발행되어 대기 서비스를 수행한다.
다) 연쇄 오류 복구 방식(Cascading Failover)
다노드 상호대기와 비슷한 방식이지만 장애 노드의 복구가 완료되기 전에 2차 장애가 발생하면 살아있는 노드가 2차 장애의 모든 서비스까지 수행하는 것으로, 최악의 경우 마지막 한 노드만 살아남아도 모든 서비스는 지속된다.
라) 분산 오류 복구 방식
성능이 매우 좋은 한 노드에서 복수의 서비스를 수행하다가 이 노드에서 장애가 발생하면 서비스의 부하에 따라 지정된 노드로 절체하는 방식이다. 예를 들어 8 CPU의 메인서버에서 DB, Mail, DNS의 세 가지 서비스가 수행되고 있다면 DB 서비스는 4 CPU의 노드로 절체하고 Mail 서비스는 2 CPU의 노드로, DNS 서비스는 1 CPU의 노드로 절체한다. 이 방식은 대기 노드를 저사양의 값싼 시스템으로 구성할 수 있다는 장점이 있다.
다. HA 클러스터링의 활용
1) 서비스의 복구
서비스 노드에서 장애가 발생하면 대기 노드가 서비스를 수행할 것이다. 장애 노드의 문제가 모두 해소되면 어떻게 원복할 것인가도 중요한 문제가 될 수 있다. 왜냐하면 계획된 절체라 하더라도 볼륨 처리와 ip 회수와 부여, 프로세스의 종료와 기동 등을 수행하면서 길 경우 몇 분, 빨라도 몇 초 정도의 다운타임 발생은 피할 수 없기 때문이다. 따라서 서비스 특성에 따라 곧바로 원복할 수도 있지만 대개 서비스가 쉬거나 사용자가 거의 없는 새벽 시간대 등을 활용해야 한다.
2) 운영 서버의 업그레이드 작업
시스템을 운영하다 보면 업그레이드나 구성을 변경해야 할 때가 있을 수밖에 없게 된다. 단일 시스템으로 운영할 경우라면 그런 작업을 위해 어쩔 수 없이 서비스 다운을 사용자에게 공지하고 사용자가 적은 야간 시간대에 작업을 해야만 한다. HA 클러스터로 구성된 환경이라면 대기 노드로 서비스를 절체하고 운영서버의 점검이나 업그레이드 작업을 수행할 수 있다. HA 클러스터의 구성 목적은 장애 발생 시의 가용성을 확보하는 것이지만 계획된 시스템다운 시에도 HA는 유용하게 활용될 수 있다.
라. HA 클러스터링의 한계
1) 다운타임
- 절체가 수행되기 위해서는 장애 노드에서 서비스가 종료되어야 한다. 예를 들어 장애 노드의 ip address를 회수하지 못한다면 대기 노드에서 그 ip를 서비스를 위해 부여해 줄 수가 없게 된다.
- 절체 진행 중 장애 노드에서 서비스를 내리고 Resource를 회수하고, 대기 노드에서 서비스를 올리는 동안의 서비스 다운타임은 피할 수 없게 된다.
2) 연쇄 장애
- 강력한 외부의 공격으로 웹서버가 다운되었다고 가정해 보자. 웹 서비스가 메일서버로 절체되었다면, 외부의 공격이 멈추지 않는 한 메일서버의 다운은 예정된 수순이 된다. 또다시 웹 서비스와 메일 서비스가 DNS 서버로 절체된다면 DNS 서비스의 장애를 피할 수 없게 되고 종국에는 모든 서비스가 중단되는 최악의 사태로 진행된다.
- 따라서 HA 클러스터로 서비스를 제공할 경우에는 이와 같은 연쇄 장애에 대비하여 서비스 팜 앞에 컨텐츠 필터링을 할 수 있는 장치를 우선적으로 설치하여야 한다.
DR(재난복구, Disaster Recovery)과 무중단 서비스 관련 정보는 다음을 기약하겠습니다.
댓글 [3]
| 번호 | 제목 | 글쓴이 | 조회 | 추천 | 등록일 |
|---|---|---|---|---|---|
| [공지] | 강좌 작성간 참고해주세요 | gooddew | - | - | - |
| 862 | 소프트웨어| '센스부족'을 통한 인터넷 광고 막기 v110107 [6] |
|
14263 | 0 | 01-06 |
| » | 서버 / IT| [강좌]이중화기술 - 가용성과 경제성 [3] | 우금티 | 14517 | 0 | 01-06 |
| 860 | 윈 도 우| 점프 리스트 목록이 날아갔을 때 해결법 [2] | 김윈도 | 10709 | 0 | 01-05 |
| 859 | 소프트웨어| Windows 버전에 따른 .NET Framework 버전 [5] |
|
9520 | 0 | 12-30 |
| 858 | 소프트웨어| .NET Framework product version |
|
6060 | 0 | 12-30 |
| 857 | 소프트웨어| 구글 크롬 펌 방지 해제 방법 올려봅니다. [8] | 찐옥수수 | 13358 | 0 | 12-29 |
| 856 | 소프트웨어| PC를 쾌적하게 사용하는 상식 13가지 [19] |
|
12819 | 0 | 12-27 |
| 855 | 소프트웨어| 블루스크린 숫자별 문제점 찾기 [9] |
|
8526 | 0 | 12-27 |
| 854 | 윈 도 우| 작업관리자에서 프로세스종료가 안될시에는? [6] |
|
44546 | 0 | 12-27 |
| 853 | 윈 도 우| God Mode 만들기 [5] | 적광 | 55465 | 0 | 12-26 |
| 852 | 소프트웨어| 개발자 도구 마음대로 다운받기! 드림스파크 [11] |
|
8094 | 0 | 12-25 |
| 851 | 서버 / IT| [팁:정보_수정] 미친 알약(ALyac) [12] | 우금티 | 14906 | 0 | 12-21 |
| 850 | 소프트웨어| 초보도 하는 유튜브 동영상 다운 받기 [8] | gooddew | 7982 | 0 | 12-19 |
| 849 | 소프트웨어| 광고 주소 찾는 초~~~~ 허접한 팁 [1] | ever | 5743 | 0 | 12-19 |
| 848 | 소프트웨어| 프로그램 설치 없이 구글 광고 차단하기 [7] |
|
8141 | 1 | 12-19 |
| 847 | 소프트웨어| 그리드 컴퓨팅 - 미확인 우주 생명체 프로젝트 [2] | Native 64 | 8122 | 0 | 12-19 |
| 846 | 윈 도 우| win7 설치 이미지 사용자 지정 [21] |
|
14031 | 0 | 12-16 |
| 845 | 윈 도 우| [팁] : 명령창 풀스크린 [7] | 우금티 | 7334 | 0 | 12-16 |
| 844 | 소프트웨어| [초보용] MS OFFICE 2010 시디키 변경 방법 [1] | gooddew | 30595 | 0 | 12-15 |
| 843 | 하드웨어| AMD 레이드 구성시 "NCQ" 과연 효과 있을까? [13] |
|
12073 | 0 | 12-13 |
한때 HA 솔루션 판매업체에서 일했었는데..
이글을 보니 감회가 새롭네요..